
The mental model when talking to ChatGPT is you are talking to a simulation of what a human labeller would say
As expected, this was a fantastic intro course (3h30) into how LLMs work, with the stated goal of giving you an intution and demistifying for what really happens when you get that stream of text back from ChatGPT, from one of OpenAI’s founding engineers Andrej Karpathy. What are each of the steps of training a model? What’s the difference between a base model and a chatbot? Why do models hallucinate? What is the difference between the GPT-4 model and the 4o model, and why is the latter better at reasoning? What are the next big areas of research in LLMs?
One fun contrast was on the one hand he demystifies the internals, and ‘who are you?’ kinds of questions to a machine, on the other hand he still has a child’s wonder at their output and their ‘creativity’. Even when you know the process, there is something profoundly human about the models as they are made from our culture.
Enjoy the notes!
Pre-training
Step 1: getting data

- Need as much text as possible from the internet, of the highest quality and diversity possible. Often use CommonCrawl, an OSS project which indexes data from 2.7B+ web pages
- Then filter & process the data, eg which languages, categories of sites do you want, e.g and end up with a ‘clean’ text-only dataset, eg FineWeb, provided by HuggingFace, which is 44 TB.
Step 2: tokenisation

- Turning each string of texts into a number/symbol. Example from the Tiktokenizer tool:

- Each model has their own tokeniser (more/less end symbols). GPT-4 has 100,277 for example. Fineweb is 15 trilliion tokens using this tokenisation
Step 3: neural network training
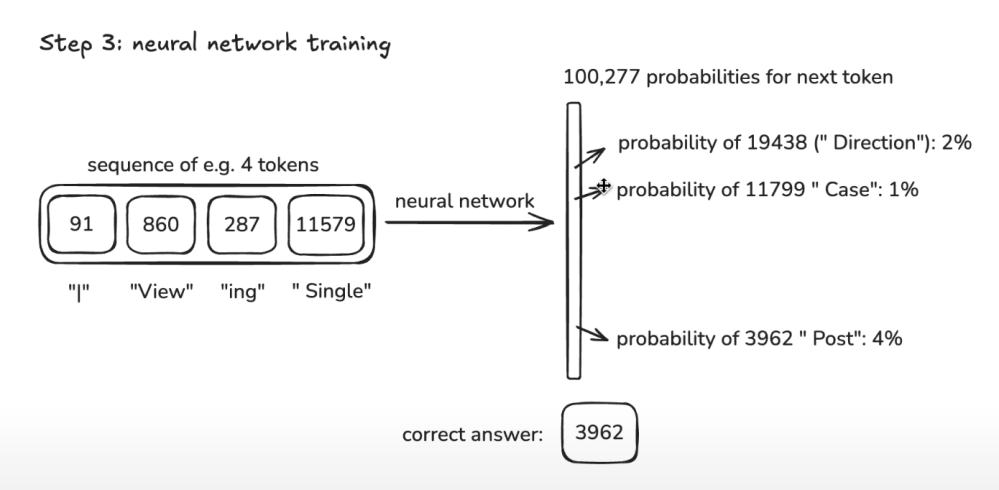
- Go through the whole data set
- for each sequence of N tokens (the context)
- array of probabilities of each of the next possible tokens, initially they are all 0
- Increase the probabilities of the tokens that are actually following each context in the data set
- Above happens in large batches of contexts in parallel, this is the very computationally heavy part
- The probabilities of each token for each set of contexts are the model ‘weights’. For example GPT-2 in 2019 had 1.6B parameters, in 2025 they have 100s of billion
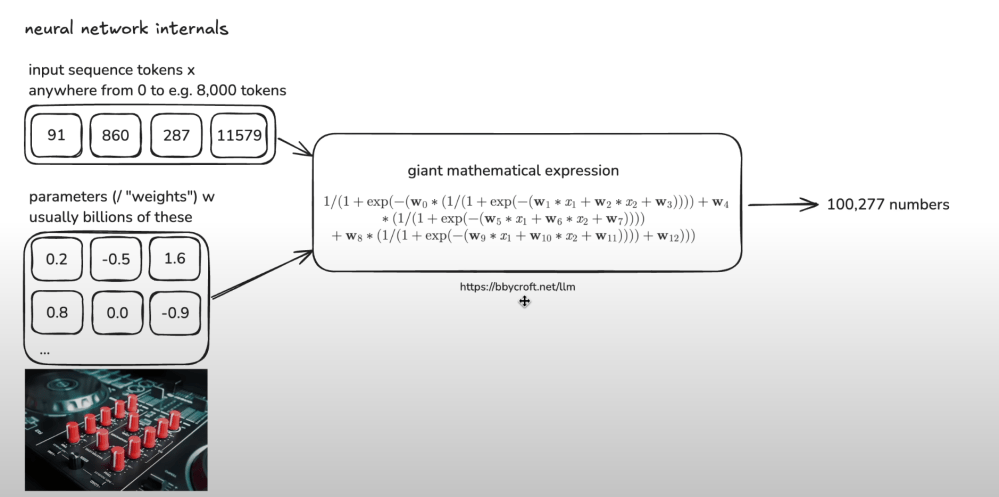
Training steps:
Embedding: Each token (word or subword) is mapped to a vector of numbers that captures its general meaning based on the training data.
- Example: The word “bank” might be embedded differently depending on whether it appears near “river” or “money”.
Self-attention: Each token looks at all other tokens in the sentence to decide how much attention to pay to them when interpreting its own meaning.
- Example: In “She poured water into the glass because it was empty,” self-attention helps determine that “it” refers to “glass”.
Multi-head attention: The model runs multiple self-attention processes in parallel. Each one can learn to focus on different types of relationships — like grammar, position, or meaning.
Feed-forward network: Each token is passed through a small neural network. This applies learned transformations to better refine the information gathered from attention.
- Example: It adjusts the meaning of “bank” further depending on context — “The bank closed at 5pm” vs. “The boat hit the river bank”.
Steps 2–4 form a transformer block. GPT = Generative Pre-trained Transformer
Stacking layers: These transformer blocks are stacked in layers, allowing the model to reprocess the sentence multiple times.
- Example: It’s like reading a sentence 96 times (as in GPT-3) and refining your understanding each time — spotting a pun, an irony, or a subtle reference on later passes.
Weights and parameters: Every layer has its own weights — numbers that get adjusted during training. These parameters act like knobs controlling how information flows and transforms.
Base models

- What you end up with post training. Not an assistant, it is just a ‘glorified autocomplete’ based on what it’s trained on. And it’s stochastic / probabilistic
- Usually released as python code + weights e.g https://github.com/openai/gpt-2
- Regurgitation: when the model cites exactly what you have from an existing source. You don’t want that, you want the statistically best answer
- In-context learning using few-shot prompt: you give the model a hint of how you want it to respond. e.g multi-shot prompt below, you give a few examples of what you want:
butterfly : 나비, ocean : 바다, whisper : 속삭임, mountain : 산, thunder : 천둥, gentle : 부드러운, freedom : 자유, umbrella : 우산, cinnamon : 계피, moonlight : 달빛, teacher :- Can use this to get better results
Post-training
Inference: the phase where a trained model is used to make predictions — without changing its parameters (which are set during training)
- Supervised fine-tuning (SFT) uses labeled data to train LLMs for domain-specific applications. Turning a base model into something useful for an assistant.
- Continue to train the base model, on a dataset of conversations of ‘good’ assistant responses to human queries, eg OpenAI used a lot of experts in specific domains & freelancers on Upwork to do this. There are also specific models making good ‘synthetic’ conversation data, eg Ultrachat
- Much cheaper/shorter process than pre-training as the conversations dataset is much smaller
- So the mental model when talking to ChatGPT is you are talking to a simulation of what a human labeller would say (pre-training knowledge combined with the post-training dataset)
Reinforcement learning
The last major state of training

- Teach the model the reasonining of how to get to the answer. You give it the right answer and make it learn how to reason
- Was happening a lot secretively until Deepseek public release which showed great perf thanks to RL
- Deepseek paper showed that the models actually perform better if they use more tokens ie longer responses. So like humans they try a lot of stuff out, backtrack, etc. Learns ‘chains of thought’


- OpenAI o1 – ‘uses advanced reasoning’ – used RL
- 4o uses SFT models
- RL is what AlphaGo used
- Reinforcement learnings from human feedback (RLHF)
- Used for arbitrary and unverifiable domains (eg humour)
- Works well because it’s much easier to get humans to rank which poem is the best out of 5 generated ones than to ask them to generate a poem
LLM psychology
Hallucinations. When LLMs make stuff up.
- In the training data set, if you have all confident-sounding answers, it will take imitate a confident-sounding answer even if it doesn’t know
- Mitigation #1: adding ‘I don’t know’ answers in the training data for things the model doesn’t know
- Mitigation #2: add a ‘tool’ for the model to go check
- Web search. Special token for starting a search, does eg a Bing search and feeds the result into the context window (which OpenAI does)
- Code tool is more reliable for arithmetic questions
The ‘who made you?’ question is often just replied to by the model with its existing data so may be wrong. Sometimes it’s special cased though
Tips
- Working memory works a lot better than recollection. So always better to give the LLM the context, eg if you want it to summarise something give it to them
- The computation for getting each next token is finite. So you want the model to spread its computation over several models. That’s why in the below example option 1 is worse, because it provided the answer straight away then the rest is post-hoc justification

Future capabilities / next frontiers
- Multimodal: You can use the same tokenisation processes for audio and video.
- Agents, long-running tasks: we will be talking about the human:agent ratio as we talk about the human:robot ratio in factories.
- Pervasive, blending with the computer
- Test-time training. Model is fixed right now. It doesn’t learn from anything that happens after the model is trained
Resources
- lmarena.ai. leaderboard of models. has been a bit gamed recently though
- ML Studio – run models locally
- Hyperbolic tool to try different base models
- Nomic Atlas – data visualisation site for AI data sets, eg conversation data for SFT
